 3 miesięcy temu
3 miesięcy temu
Badacze Apple zaprezentowali SlowFast-LLaVA-1.5 – rodzinę modeli językowych (1B, 3B i 7B parametrów) zoptymalizowanych pod kątem zrozumienia długich filmów.
Model łączy analizę obrazów i wideo, a dzięki systemowi dwóch strumieni (szybkiego i wolnego) potrafi efektywnie wyłapywać szczegóły oraz ruch w czasie.
SF-LLaVA-1.5 przewyższa większe modele na benchmarkach LongVideoBench i MLVU, a dodatkowo radzi sobie z zadaniami obrazowymi (OCR, matematyka, wiedza ogólna). Trenuje się go wyłącznie na publicznych zbiorach danych i jest open source (GitHub, Hugging Face).
Mając to na uwadze, naukowcy twierdzą, że:
Podejście to może pomijać niektóre najważniejsze klatki w długich filmach i wprowadzać model w błąd co do prędkości odtwarzania wideo. (…) Wydajność SF-LLaVA-1.5 można dodatkowo poprawić, dostrajając wszystkie parametry, w tym koder wizualny. Stwierdziliśmy jednak, iż nie jest to trywialne w przypadku długich wideo LLM ze względu na wysoki koszt pamięci GPU związany z buforowaniem wartości aktywacji. Przyszłe badania mogą obejmować integrację technik oszczędzania pamięci, takich jak stochastyczne BP.
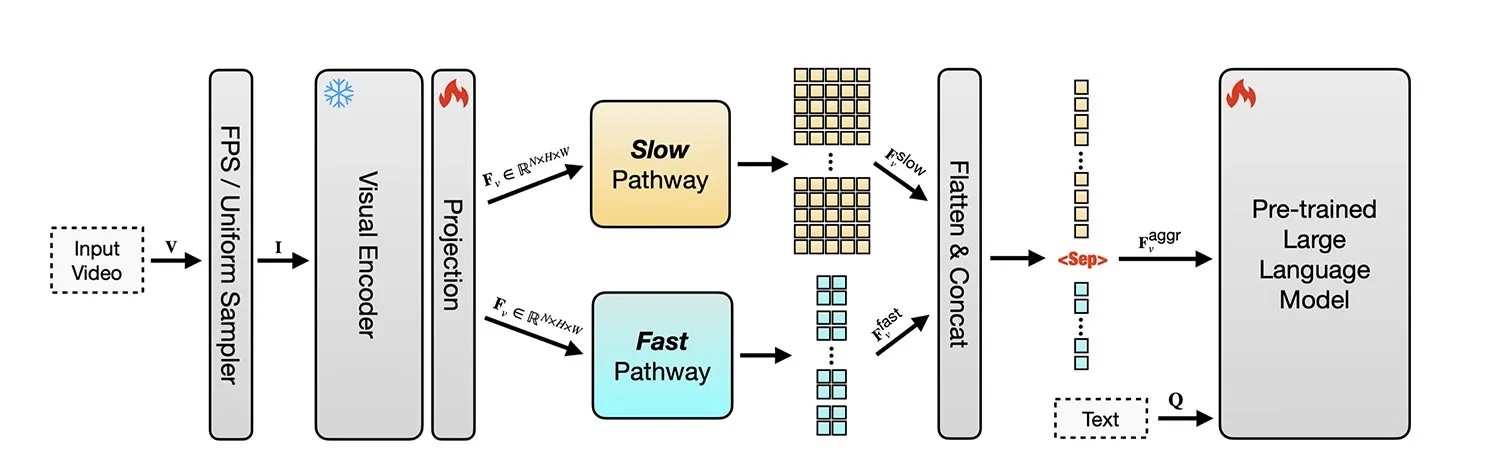
Ograniczeniem jest maksymalna liczba 128 analizowanych klatek, co może prowadzić do pomijania istotnych fragmentów w bardzo długich nagraniach. Mimo to model uznano za stan obecnej sztuki w analizie wideo.
Pełne omówienie modelu znajdziecie tutaj.
Jeśli artykuł Apple opracowało nowy model AI do analizy długich wideo nie wygląda prawidłowo w Twoim czytniku RSS, to zobacz go na iMagazine.
















